
Mistral Launches OCR 4: Document AI for Enterprise RAG Pipelines
Mistral released OCR 4 on June 23, 2026, a document intelligence model that returns structured output with bounding boxes, block labels, and confidence scores. Here is what changed, how it prices against Google and AWS, and why the self-hosting option matters for regulated industries.
Mistral Launches OCR 4: What the New Document AI Model Does and Why It Matters for Enterprises
Mistral released OCR 4 on June 23, 2026. It is the company's fourth optical character recognition model in roughly 15 months, but calling it an OCR upgrade undersells what actually shipped. OCR 4 does not just pull text from a document. It returns the document's structure: every block labeled, localized, and scored for confidence. That shift is what makes it useful for enterprise AI pipelines, not just digitization projects.
This post covers what OCR 4 does, how it benchmarks against rivals, what the self-hosting option means for regulated industries, and why Mistral is really selling an enterprise AI stack, not a document scanner.
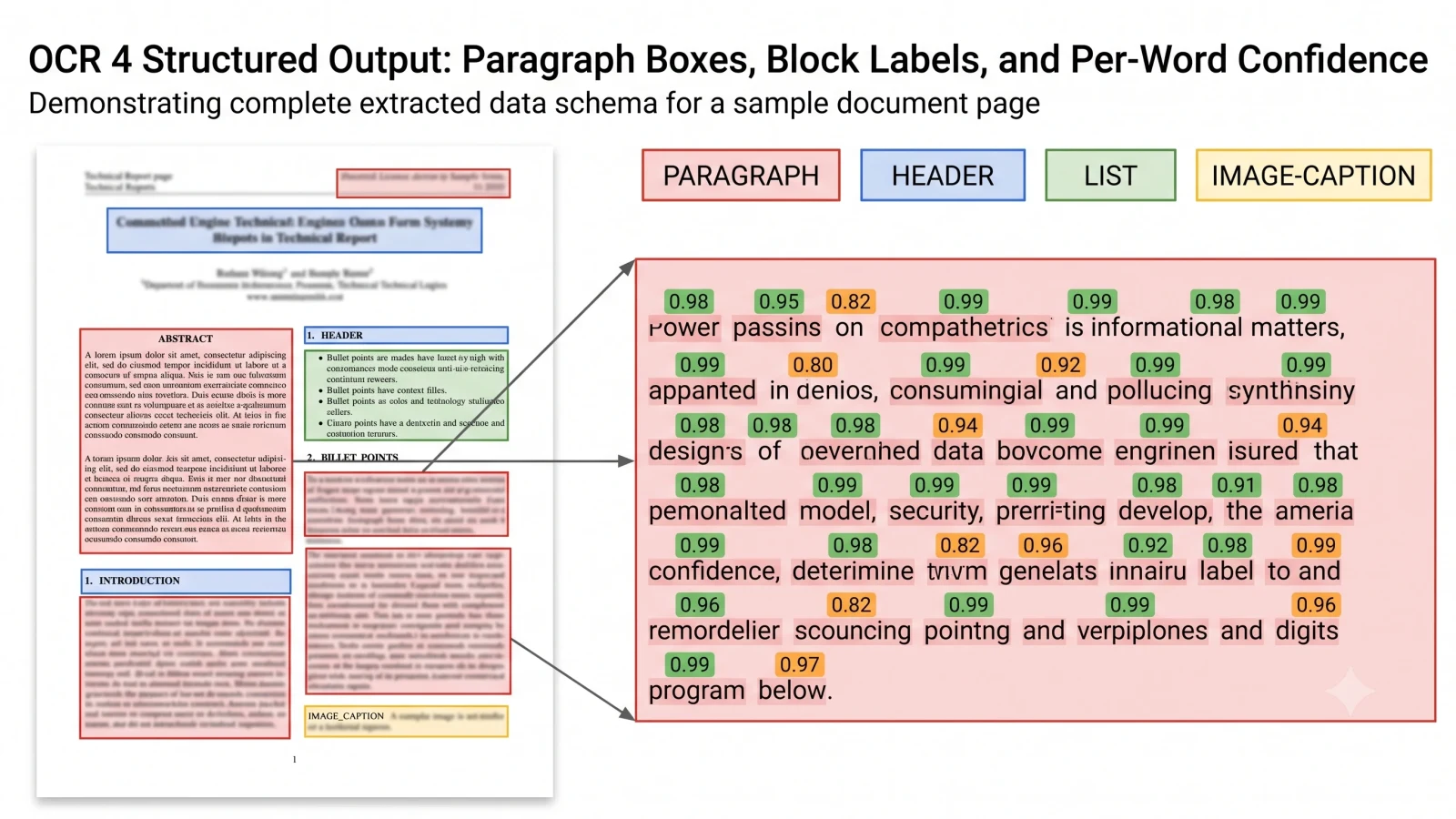
What Did Mistral Actually Ship With OCR 4?
OCR 4 is a document intelligence model that extracts both content and structure from documents, returning text alongside bounding boxes, block-type labels, and per-word confidence scores on every page.
Previous versions of Mistral OCR mainly converted documents into text and tables. OCR 4 goes further. Every extracted block comes with a label (title, table, equation, signature, and others), plus a confidence score at both the page and word level. That scoring is what lets teams build confidence-gated pipelines, routing low-confidence regions to human reviewers while auto-approving the rest.
Supported formats include PDF, DOC, PPT, and OpenDocument files. The model covers 170 languages across 10 language groups, with measurable gains on low-resource languages where most competitors degrade. On a single GPU, it processes up to 2,000 pages per minute.
There are two modes available through the same API endpoint:
- OCR 4 returns raw structured content: text, markdown, bounding boxes, block types, confidence scores. Priced at $4 per 1,000 pages, or $2 per 1,000 pages via the batch API.
- Document AI layers custom prompts, JSON schema conversion, and image annotations on top of the OCR output. Priced at $5 per 1,000 pages.
The model is live now on la Plateforme, Amazon SageMaker, and Microsoft Foundry. Snowflake Parse Document support is coming soon.
How Does OCR 4 Benchmark Against Other Models?
OCR 4 scored 85.20 on OlmOCRBench and 93.07 on OmniDocBench, placing first among the systems Mistral tested. In a blind human evaluation across 600-plus real-world documents in over 12 languages, independent reviewers preferred OCR 4's output 72% of the time on average.
One early enterprise benchmark is worth reading carefully. Aidan Donohue, AI Engineer at Rogo, said:
We benchmarked Mistral OCR 4 against the leading agentic document parsers across a chart and figure dense financial QA dataset and reached equivalent accuracy at roughly 8x lower cost and 17x lower latency. For production use cases at scale, that delta compounds fast.
That said, Mistral itself flags limitations in both public benchmarks. Ground-truth annotation errors penalize correct outputs. Equivalent mathematical notation expressed differently scores as a mismatch. Multi-column reading-order assumptions create false errors. The 72% win rate methodology has not been publicly disclosed in enough detail for independent verification.
The honest takeaway: the benchmark numbers are directional, not definitive. Independent reviewers and AI Weekly recommend testing OCR 4 on your own documents before committing to a production deployment.
How Does OCR 4 Compare to Google, Amazon, and Azure?
OCR 4 is priced at $4 per 1,000 pages standard and $2 per 1,000 pages in batch mode. That number needs context to mean anything.
AWS Textract basic OCR runs around $1.50 per 1,000 pages. But that is not the right comparison. The structured extraction tier, which is what OCR 4 is actually competing against, reaches approximately $65 per 1,000 pages. [3] Google Document AI basic OCR drops to $0.60 per 1,000 pages at high volume, but again, that is basic text extraction. Azure Document Intelligence sits around $10 per 1,000 pages for structured work.
At $4 per 1,000 pages, Mistral is cheaper than the structured tiers from Google, Amazon, and Azure. Rogo's reported 8x cost advantage over leading agentic document parsers is consistent with what independent comparisons show for that market segment.
Baidu's Unlimited-OCR is worth mentioning: it is free under an MIT license and runs on standard GPU hardware. No managed API, no SLA, no enterprise deployment packaging. OCR 4 is a commercial product with per-page pricing, self-hosted deployment, multi-platform distribution, and enterprise support structures. They are solving different problems for different buyers.
The broader competitive field includes ABBYY Vantage, Kofax (now Tungsten Automation), and a growing set of open-weight models. OCR 4's structural differentiator is the bounding boxes feature. When combined with retrieval-augmented generation, bounding boxes let AI assistants provide clickable citations that link directly to the exact location in the source document. Basic text extraction cannot do that.
Why Can Enterprises Self-Host OCR 4?
OCR 4 runs in a single container, making fully self-hosted deployment possible for organizations that cannot send sensitive documents to third-party cloud APIs.
Healthcare, finance, and legal teams are the obvious targets. These are the industries where a document leaving your infrastructure is not just a preference issue but a compliance requirement. The model's compact size means it is cost-viable for high-volume deployments even on-premises.
The timing is not accidental. The EU AI Act's fine enforcement provisions take effect August 2, 2026. That is about six weeks from now. European enterprises evaluating document AI vendors are under fresh pressure to assess exactly where documents go and who processes them. Mistral, as a French company with explicit European sovereignty positioning, is building directly toward that pressure.
The broader infrastructure shift reinforces the opportunity. Estimates from publicly available data show 55% of enterprise AI inference now runs on-premises or at the edge, up from 12% in 2023. That structural shift toward sovereign AI deployments is the environment OCR 4's single-container architecture is built for.
Mistral has also signed the GPAI Code of Practice, alongside Anthropic, Google, IBM, Microsoft, and OpenAI. That is relevant for enterprises that need verifiable compliance commitments from their AI vendors.
What Is Mistral's Bigger Plan With OCR 4?
OCR 4 is not really an OCR story. It is a wedge product for enterprise AI budgets.
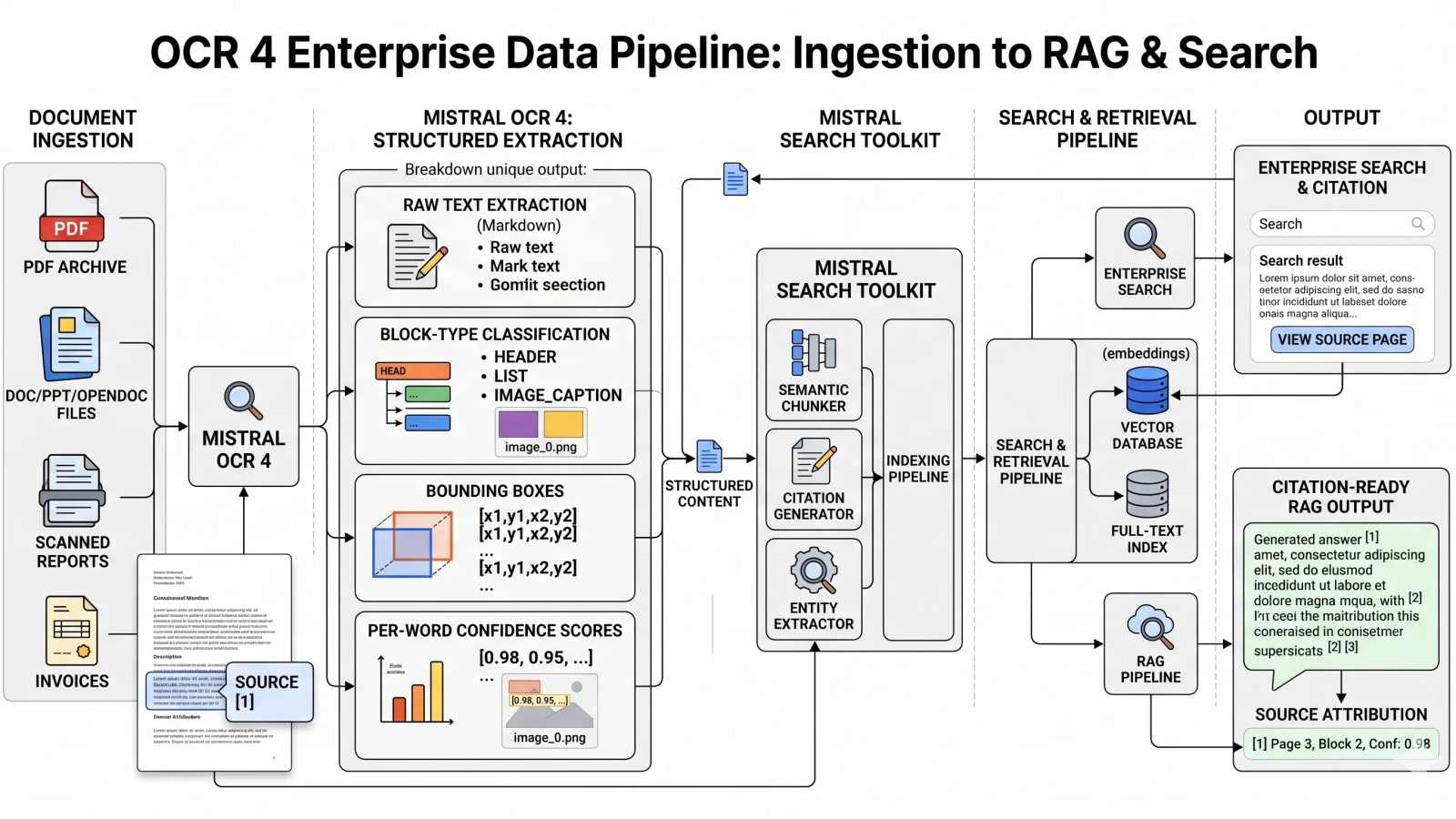
The model feeds directly into Mistral's Search Toolkit, the company's open-source composable search framework announced at the AI Now Summit 2026. In that architecture, OCR 4 sits at the ingestion layer: it converts raw documents into citation-ready, structurally classified input, which then flows into retrieval-augmented generation and enterprise search pipelines. No intermediate preprocessing layer required.
From there, the stack logic is clear. Teams that adopt OCR 4 for document ingestion are looking at Medium 3.5 for reasoning and the Vibe agentic platform for task execution as their natural next steps. This is how Mistral builds pipeline lock-in without building a general-purpose model that can match OpenAI or Anthropic head-on.
Kimmi Grewal, VP of AI Ecosystem Partnerships at Microsoft, confirmed the partnership's direction:
The availability of Mistral Document AI with OCR 4 in Microsoft Foundry marks an important milestone in our partnership. Together, we're enabling customers to bring advanced, structured document understanding directly into their AI workflows, combining Mistral's innovation with Microsoft's enterprise platform to deliver scalable, trusted solutions for real-world business needs.
The financial stakes are real. According to Le Monde, Mistral is targeting €1 billion in revenue for 2026, up from €200 million in 2025. That is a 5x jump that needs new enterprise revenue streams to materialize fast. Bloomberg recently reported the company is in early discussions to raise roughly €3 billion at a €20 billion valuation, nearly double the €11.7 billion valuation from its September 2024 Series C.
OCR 4 is part of how that revenue story gets told to investors. The global intelligent document processing market was valued at $10.57 billion in 2025 and is projected to reach $91.02 billion by 2034, according to Fortune Business Insights. Europe's portion was $805 million in 2025 and is growing at 13.4% annually through 2034, according to Market Data Forecast, with strict data sovereignty laws accelerating adoption of on-premises solutions.
Mistral has roughly 1,000 employees and has raised about $4 billion total, a fraction of what its US rivals have taken in. It is not going to win a general-purpose model race. Differentiated enterprise infrastructure built around sovereignty and structured document intelligence is a more defensible position, and OCR 4 is a concrete step in that direction.
Who Should Use OCR 4 Right Now?
Three types of teams have a clear reason to evaluate OCR 4 today.
- Regulated industries with document-heavy workflows. Healthcare, financial services, and legal operations that cannot route documents through external cloud APIs now have a credible structured-extraction option that stays entirely on their own infrastructure. The self-hosted single-container deployment removes the main blocker.
- Teams building RAG or enterprise search pipelines. OCR 4 produces citation-ready, semantically chunked output that feeds directly into Mistral's Search Toolkit without preprocessing. Early users are already converting invoices into structured fields, digitizing company archives, and extracting clean text from technical reports for search indexing.
- Organizations with multilingual document archives. OCR 4 leads across 8 of 10 language groups on Mistral's Crawl Multilingual benchmark and shows measurable gains on low-resource languages where Google, Amazon, and Azure document intelligence products degrade. For archives with Arabic, Southeast Asian, or specialized technical documents, the coverage difference matters.
One practical cost check: processing a 100,000-page corporate archive in batch mode runs $200 at $2 per 1,000 pages. That makes large-scale digitization projects economically viable for the first time at many organizations that have been putting them off.
A production webinar with demos is scheduled for July 7, 2026. If you are evaluating OCR 4 for a specific document type, that is the fastest path to seeing what the bounding boxes and confidence scores look like on real material before committing to the API.
Sources
- Mistral launches OCR 4, turning document extraction into a full enterprise AI play --> VentureBeat, June 2026; used for strategic context, Mistral revenue targets, fundraising, and employee count
- Mistral OCR 4: SOTA OCR for Document Intelligence --> Mistral official announcement; used for feature details, pricing, benchmark scores, Rogo quote, Grewal/Microsoft quote, and use cases
- Mistral OCR 4 Ships: Structure-Aware Document AI Runs On Your Infrastructure --> TechTimes, June 24, 2026; used for competitive pricing breakdown (AWS, Google, Azure) and benchmark caveats
- Mistral AI Tackles Unstructured Data Challenge With OCR 4 --> AI Business, June 24, 2026; used for bounding boxes competitive differentiation and RAG citation feature
- Mistral AI Launches OCR 4, Claims 72% Win Rate Over Rivals in Blind Tests --> MLQ.ai; used for self-hosting competitive context, GPAI Code of Practice, on-prem inference share stats
- Intelligent Document Processing Market Size --> Fortune Business Insights; used for global IDP market size ($10.57B in 2025, $91.02B by 2034)
- Europe Intelligent Document Processing Market Size --> Market Data Forecast; used for Europe IDP market size ($805M in 2025, 13.4% CAGR)

FAQ
Frequently Asked Questions
[ Related ]
More in News
Researchers Introduce Self-Harness: AI Agents That Rewrite Their Own Rules
Shanghai AI Lab researchers published Self-Harness, a framework that lets AI agents rewrite their own operating scaffolding. They gained up to 21.4 percentage points on Terminal-Bench 2.0 without touching model weights.
Microsoft Scout Is the OpenClaw Based AI Assistant Coming for Office Work
Microsoft Scout brings OpenClaw-style personal agents into Microsoft 365. Here is what it does, how it differs from Copilot, and why privacy controls matter.

Anthropic Confidentially Files for IPO, Beating OpenAI to Wall Street
Anthropic confidentially filed a draft S-1 with the SEC on June 1, 2026, days after a $65 billion raise pushed its valuation to $965 billion, edging ahead of OpenAI in the race to go public.
ChatGPT Falls Below 50% Market Share for the First Time
For the first time since its launch, ChatGPT holds less than half the AI assistant market. Gemini and Claude are gaining ground fast. Here is what the numbers say and what it means for everyday AI users.

Why the Government Just Forced a Total Shutdown of Anthropic’s Newest AI Models
The US government halted Anthropic's Claude Fable 5 and Mythos just days after launch over major national security and autonomous exploit risks.

OpenAI Launches Partner Network With $150 Million Investment
OpenAI has launched a new Partner Network and is putting $150 million behind it. The program brings together consulting firms and tech companies to help businesses use AI in real workflows.

U.S. Government Shuts Down Anthropic Claude Fable 5 & Mythos
The U.S. government ordered Anthropic to immediately cut off global access to Claude Fable 5 and Claude Mythos 5, citing national security concerns. Anthropic complied but publicly disagreed with the decision.

How an Astrophysicist Is Using OpenAI Codex to Simulate Black Holes
A researcher from the University of Arizona is using Codex to generate and test algorithms that could finally make black hole plasma simulations realistic and the approach has implications for how AI fits into serious scientific work.