Researchers Introduce Self-Harness: AI Agents That Rewrite Their Own Rules
Shanghai AI Lab researchers published Self-Harness, a framework that lets AI agents rewrite their own operating scaffolding. They gained up to 21.4 percentage points on Terminal-Bench 2.0 without touching model weights.
Researchers Introduce Self-Harness: The AI Framework That Fixes Its Own Scaffolding
Researchers at Shanghai Artificial Intelligence Laboratory have published a paper showing that AI agents can iteratively rewrite their own operating rules. Not the model weights. Just the surrounding scaffolding. They gain up to 21.4 percentage points in task completion on Terminal-Bench 2.0. The paper is titled "Self-Harness: Harnesses That Improve Themselves" and is available on arXiv (2606.09498).
No retraining. No human prompt engineers tweaking instructions between runs. The agent identifies its own failure patterns, proposes fixes, checks that the fixes actually work, and applies them.
What is an AI "harness" and why does it matter?
An AI harness is everything that wraps around a language model during deployment: system prompts, tool definitions, retry logic, memory management, verification rules, and runtime adapters that connect the model to its environment. The model is the engine. The harness is the car.
This is not a minor detail. Aakash Gupta, who covers product growth and AI infrastructure, put it plainly in a widely shared analysis: Manus rewrote their harness five times in six months using the same underlying models. LangChain re-architected their Deep Research harness four times in one year, not because the models changed. The performance gap between Claude Code and a raw Claude API call is almost entirely a harness gap.
The problem is that most harnesses are designed once and then frozen. They get built by engineers who make their best guesses about how the model will behave, shipped, and rarely touched again. But models make mistakes in patterns. The same categories of failures show up run after run, and the harness just lets them repeat.
Self-Harness is a framework designed to break that cycle.
What is Self-Harness and how does it work?
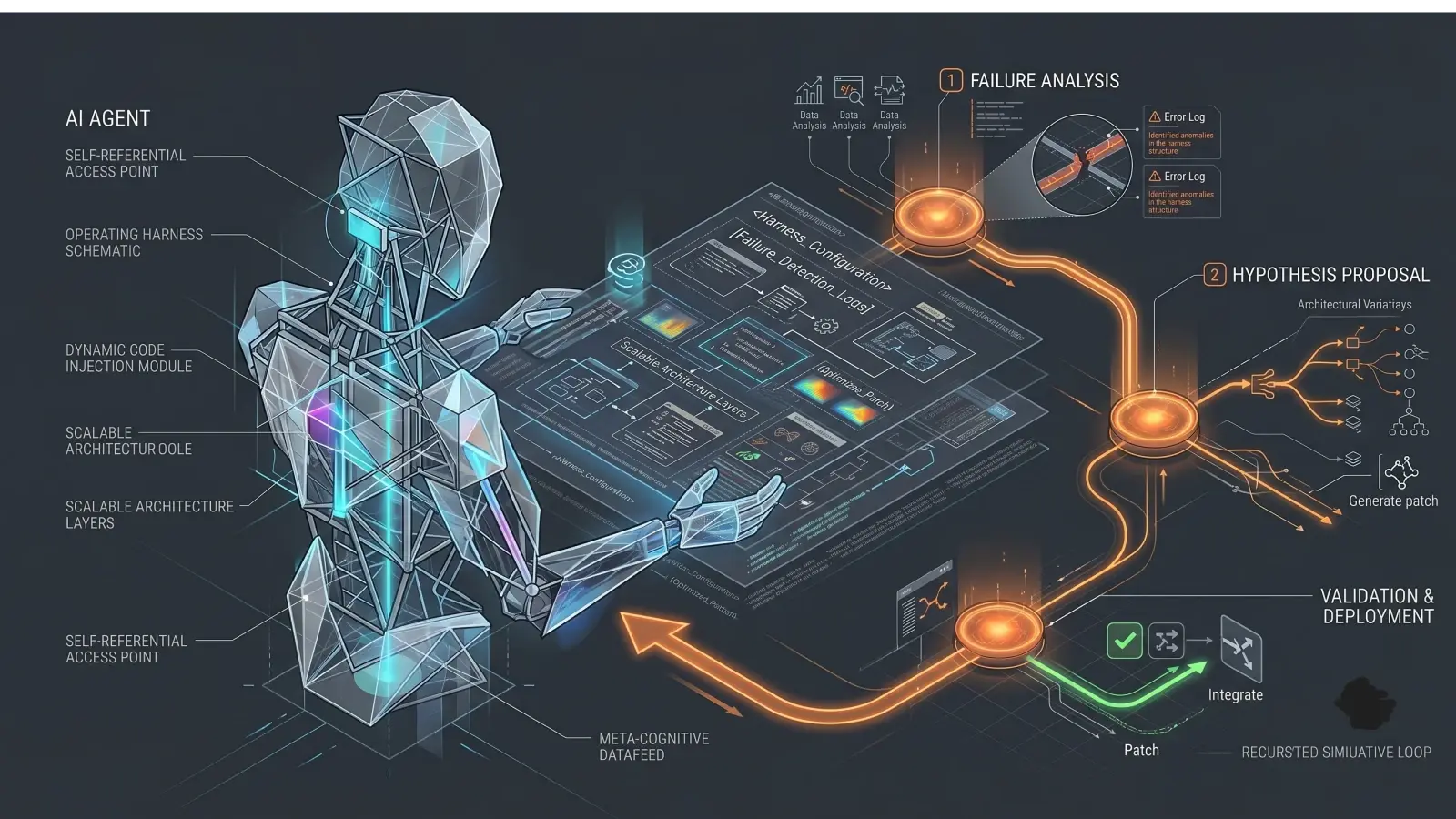
Self-Harness treats the harness as a learnable artifact. A fixed LLM runs tasks, watches itself fail, proposes edits to the harness, and only applies edits that survive regression testing. The model weights never change. The harness does.
The loop has three stages:
Weakness Mining. The agent runs a suite of tasks and its execution traces are analyzed to find recurring failure patterns. Not random failures. Patterns. If the model keeps timing out on a certain class of tasks, or keeps misformatting tool calls, those are candidates.
Harness Proposal. For each identified failure pattern, the agent proposes small, targeted edits to the harness. These edits are minimal by design. The goal is to fix specific, verified problems, not rewrite everything from scratch.
Proposal Validation. Each proposed edit is tested against held-in and held-out tasks. If an edit causes regressions (other tasks that were passing start failing), it gets rejected. Only edits that pass a conservative acceptance rule get applied.
The same fixed LLM backend does all three steps. Elvis Saravia, a researcher who tracks AI systems closely, described the implication: "Most of the agent scaffolds we rely on today are built once and remain frozen or mostly unchanged. The harness, like the skills, needs to evolve with new models. What if the scaffold rewrites itself?"

What results did Self-Harness achieve on Terminal-Bench 2.0?
Terminal-Bench 2.0, published as a conference paper at ICLR 2026, is a benchmark of 89 tasks covering machine learning, security, system administration, and data science. Tasks require agents to complete real-world operations in a sandboxed terminal using Bash commands, verified by pytest. Some tasks take expert engineers 24 hours. One task, fixing the OCaml garbage collector after a failed optimization, takes junior engineers around 240 hours.
The researchers tested Self-Harness on three model backends: MiniMax M2.5, Qwen 3.5, and GLM-5. Starting from a minimal baseline harness, the Self-Harness loop improved pass rates across all three:
- MiniMax M2.5: 40.5% to 61.9% (up 21.4 percentage points)
- Qwen 3.5: 23.8% to 38.1% (up roughly 14 percentage points)
- GLM-5: 42.9% to 57.1% (up roughly 14 percentage points)
On held-out tasks, ones the harness had not seen during the improvement loop, gains reached up to 21.4 percentage points, according to technical summaries of the paper.
One note on the "60%" figure that has circulated in press coverage: that number comes from calculating the relative improvement on MiniMax M2.5 (40.5% to 61.9% is about a 52.8% relative gain). The primary paper reports absolute percentage-point gains, not a 60% absolute improvement. Both the gain and the framing are worth understanding clearly.
How is Self-Harness different from other self-improvement research?
The self-improvement space has grown crowded. Projects like AI Scientist, AlphaEvolve, Godel Agent, and the Darwin Godel Machine all explore agents that modify some part of themselves over time. Self-Harness occupies a specific, narrower position in that space.
The core distinction is what gets modified. Self-Harness only changes the harness: prompts, tools, and runtime logic. The base model weights stay frozen. This contrasts with a concurrent paper, SIA (Self Improving AI, arXiv:2605.27276), which updates both the harness and the model weights simultaneously. SIA is more powerful but also more complex and harder to audit.
Self-Harness prioritizes auditability. The acceptance rule is conservative by design. Every applied edit is small and tied to a specific, verified failure. This means the changes are explainable, and the improvements are grounded in regression evidence rather than optimism.
The researchers position this as harness engineering becoming automatic, the same way compilers automated low-level code optimization while keeping the programmer's logic visible.
What are the limitations of Self-Harness?
The framework depends on verifier quality. Regression tests catch regressions, but only the regressions the tests cover. Weak or incomplete verifiers mean the acceptance rule lets through changes it should not. The researchers note this directly: a conservative acceptance rule can also slow progress when the verifier is strong but overly cautious.
Harness edits are model-specific. An improved harness for MiniMax M2.5 does not transfer to Qwen 3.5. Each model has its own failure modes, and the improvements generated by the loop are calibrated to those failure modes specifically.
The paper is a preprint. It has not gone through peer review as of this writing. The benchmark gains are real and reported with specific numbers, but independent replication has not been published.
Finally, the method does not touch model weights. That is a feature. It means no retraining cost, no risk of catastrophic forgetting, no change to the base model's behavior outside the harness context. But it also means there is a ceiling. Harness edits cannot fix things that are genuinely beyond the model's capability.
Why does this matter for people who use AI tools?
The practical implication is sharper than it might look. When you pick between Claude Code and raw Claude, between Cursor and a direct GPT-5 API call, you are mostly picking a harness. The model underneath is often the same or similar. The harness is the differentiator.
Self-Harness suggests that the work of optimizing that wrapper, which right now is mostly done by humans experimenting with prompts and configurations, can be automated using the model itself. A deployed agent could, in principle, spend its first hundred runs improving its own operating context without any human intervention.
That said, the current results are on a specific benchmark with strong verifiers. Terminal-Bench 2.0 has clear pass/fail criteria enforced by pytest. Real-world deployments rarely have that kind of clean signal. The gap between a benchmark improvement and a production improvement is real.
What the paper does establish clearly is that the harness is not a static artifact. It is something that can be learned, and learning it from the agent's own failures is a valid and measurable strategy. Whether Self-Harness becomes the standard way to do that, or whether it gets absorbed into broader self-improvement frameworks like SIA, is an open question.
The more immediate lesson: the wrapper around your model is worth investing in. Self-Harness is early evidence that the wrapper can invest in itself.
Sources
- Self-Harness: Harnesses That Improve Themselves (arXiv:2606.09498) --> Primary paper, all claims about the framework and results
- ExplainX.ai — What Is Self-Harness? Complete Guide --> Technical summary and pass rate figures
- Terminal-Bench 2.0 (ICLR 2026 conference paper) --> Benchmark description and task details
- SIA: Self Improving AI with Harness & Weight Updates (arXiv:2605.27276) --> Comparison framework
- Aakash Gupta — 2025 Was Agents. 2026 Is Agent Harnesses. --> Harness context and Manus/LangChain examples
- Elvis Saravia on X (@omarsar0) --> Quote on frozen scaffolds
- AlphaSignal AI — How to Let a Fixed Model Rewrite Its Own Harness --> Technical walkthrough
- Antoine Buteau — Agent Harnesses Can Learn From Their Own Failures --> Author analysis with model names
- BemiAgent — Self-Harness: Agents That Improve Their Own Harnesses --> Experimental detail summary

FAQ
Frequently Asked Questions
[ Related ]
More in News
Microsoft Scout Is the OpenClaw Based AI Assistant Coming for Office Work
Microsoft Scout brings OpenClaw-style personal agents into Microsoft 365. Here is what it does, how it differs from Copilot, and why privacy controls matter.

Anthropic Confidentially Files for IPO, Beating OpenAI to Wall Street
Anthropic confidentially filed a draft S-1 with the SEC on June 1, 2026, days after a $65 billion raise pushed its valuation to $965 billion, edging ahead of OpenAI in the race to go public.
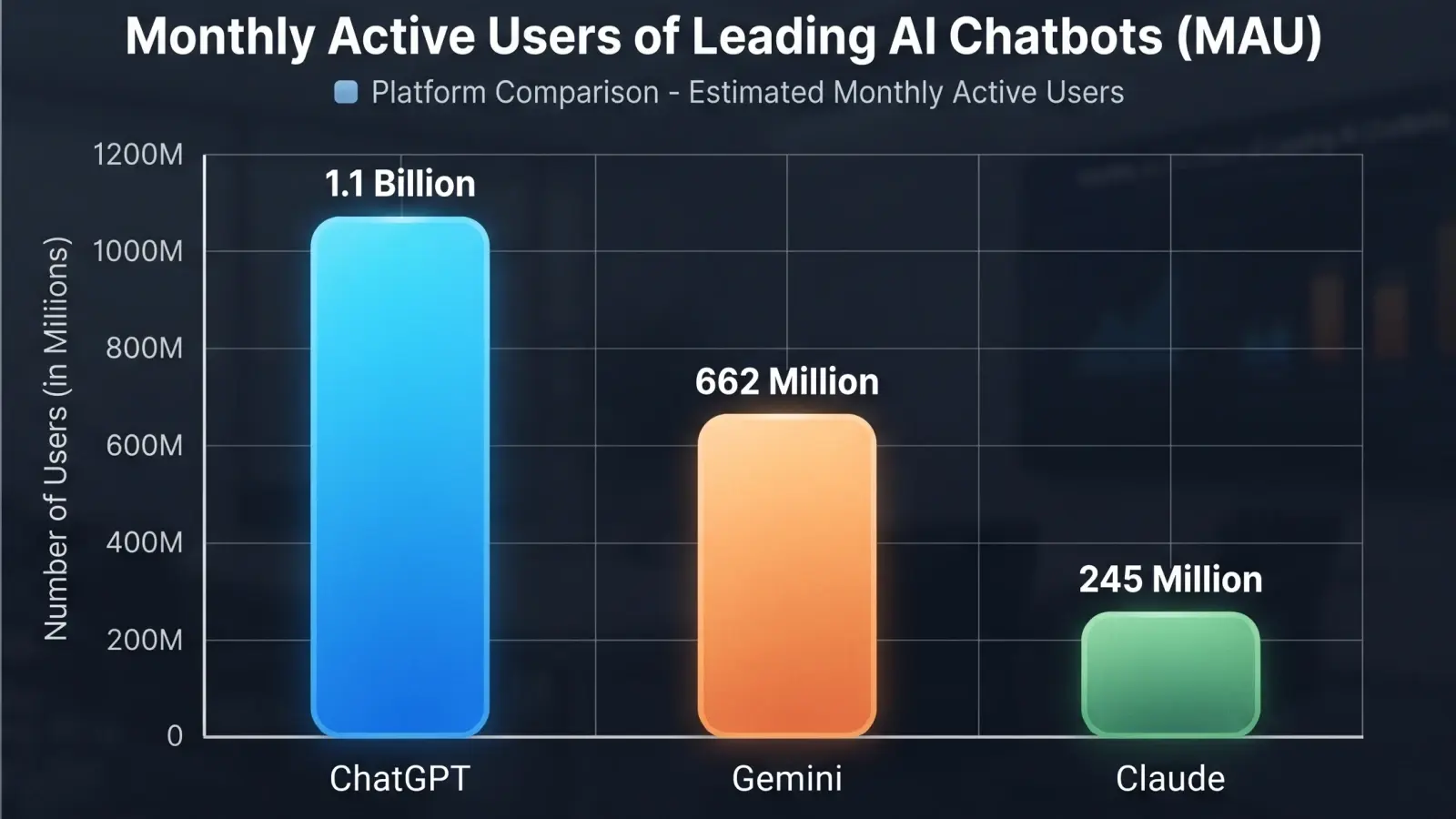
ChatGPT Falls Below 50% Market Share for the First Time
For the first time since its launch, ChatGPT holds less than half the AI assistant market. Gemini and Claude are gaining ground fast. Here is what the numbers say and what it means for everyday AI users.

Why the Government Just Forced a Total Shutdown of Anthropic’s Newest AI Models
The US government halted Anthropic's Claude Fable 5 and Mythos just days after launch over major national security and autonomous exploit risks.

OpenAI Launches Partner Network With $150 Million Investment
OpenAI has launched a new Partner Network and is putting $150 million behind it. The program brings together consulting firms and tech companies to help businesses use AI in real workflows.

U.S. Government Shuts Down Anthropic Claude Fable 5 & Mythos
The U.S. government ordered Anthropic to immediately cut off global access to Claude Fable 5 and Claude Mythos 5, citing national security concerns. Anthropic complied but publicly disagreed with the decision.

How an Astrophysicist Is Using OpenAI Codex to Simulate Black Holes
A researcher from the University of Arizona is using Codex to generate and test algorithms that could finally make black hole plasma simulations realistic and the approach has implications for how AI fits into serious scientific work.